- Products ProductsLocation Services
Solve complex location problems from geofencing to custom routing
PlatformCloud environments for location-centric solution development, data exchange and visualization
Tracking & PositioningFast and accurate tracking and positioning of people and devices, indoors or outdoors
APIs & SDKsEasy to use, scaleable and flexible tools to get going quickly
Developer EcosystemsAccess Location Services on your favorite developer platform ecosystem
- Documentation DocumentationOverview OverviewServices ServicesApplications ApplicationsDevelopment Enablers Development EnablersContent ContentHERE Studio HERE StudioHERE Workspace HERE WorkspaceHERE Marketplace HERE MarketplacePlatform Foundation and Policy Documents Platform Foundation and Policy Documents
- Pricing
- Resources ResourcesTutorials TutorialsExamples ExamplesBlog & Release Announcements Blog & Release AnnouncementsChangelog ChangelogDeveloper Newsletter Developer NewsletterKnowledge Base Knowledge BaseFeature List Feature ListSupport Plans Support PlansSystem Status System StatusLocation Services Coverage Information Location Services Coverage InformationSample Map Data for Students Sample Map Data for Students
- Help
Archive stream data
The HERE Workspace allows you to archive stream data so that you can later query and process that data for non-real-time use cases. For example, if you want to run a batch process daily to find all pothole detection events recorded that day in the area surrounding a given city, you can use an index layer to index the pothole detection events by event time, event type, and location, and then archive the data. You can then query the data every 24 hours for pothole events in the area of the city as part of your batch process.
The following diagram illustrates the overall process of archiving stream data, then querying it:
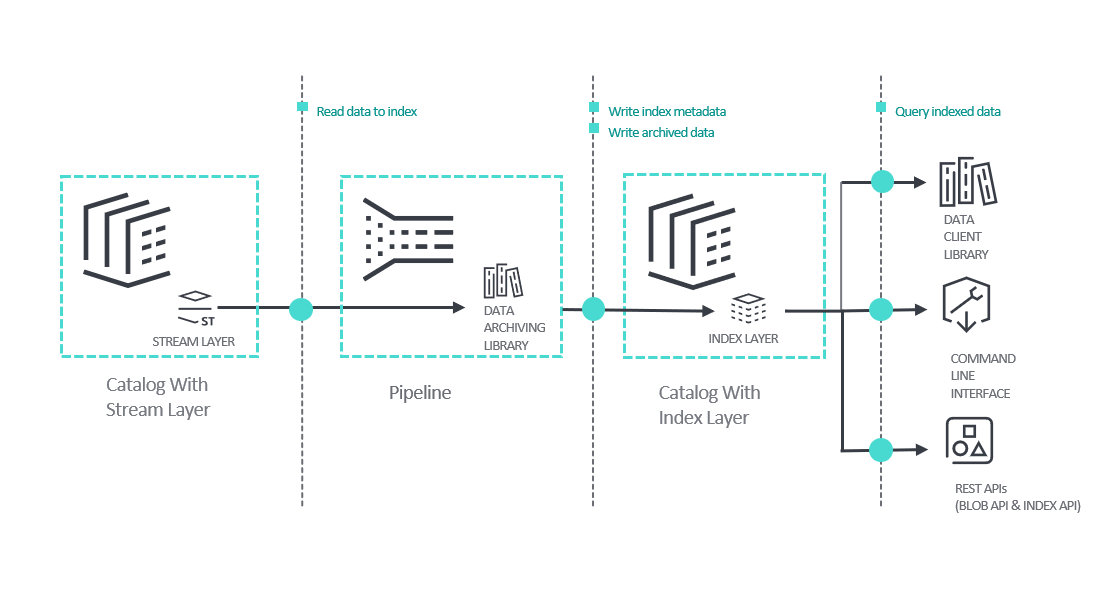
The key points in the diagram are:
-
Data from the stream layer is archived by an application that you create and run as a platform pipeline. The archiving application uses the Data Archiving Library which is a Java library that reads data from a stream layer, aggregates it, and indexes it to the index layer. For more information, see:
-
The index layer contains the archived data and indexing attributes. It is a layer in a separate catalog from the stream layer.
-
Once data is archived, there are multiple ways of querying the data:
- The Data Client Library provides Java/Scala libraries for reading data from index layers.
- The Command Line Interface allows you to read data from an index layer from a command line or script.
- The REST APIs Index and Blob can be used together to query and read the indexed data. The Index API returns the data handles for the data that matches your query. For example, if you query for events from a specific time frame and location, the response will contain the data handles for those events. Once you have the data handles that match your query criteria, you can use them to get the corresponding data using the Blob API.
Comparison of index layer interfaces
There are multiple ways to interact with the index layer.
- Data Archiving Library: Use the Data Archiving Library to develop a custom application in Java which can run in a pipeline. Using the Data Archiving Library is the recommended way to store stream layer messages into an index layer. With the Data Archiving Library, you only need to implement the library's user-defined functions in your application to extract the indexing attributes for each message. Once you have your application created, you can package it then run the application in a pipeline. Note that the Data Archiving Library is only for writing to an index layer. You cannot use it to query data.
- Data Client Library: The Data Client Library provides Java and Scala APIs that you can use to interact with index layer. If the Data Archiving Library does not satisfy your requirements and you want to develop a custom application, then the Data Client Library is the recommended way to work with an index layer.
- REST API: Use the REST API if you want to create an application with a language that the Data Client Library does not support. You can use the REST API to interact with index layer.
- Command Line Interface: Use the command line interface (CLI) to work with an index layer from a command line or script.
Creating an archiving solution
To create an archiving solution for a stream layer, follow these steps.
Step 1: Create a stream layer
If you do not already have a stream layer whose data you want to archive, create a stream layer. For more information, see Create a layer.
Step 2: Create an index layer
In a different catalog than the one that contains the stream layer you want to archive, create an index layer. For more information, see Create a layer.
Step 3: Create an archiving application
The archiving process is performed by an application you create and run in a pipeline. The easiest way to create an application is to start with one of the example applications included with the HERE Data SDK. These examples show how to use the Data Archiving Library to store data.
Creating an archiving application involves these steps:
- Implement the user-defined functions provided in the Data Archiving Library.
- Configure the
application.conffile. - Package the application into a fat JAR file.
See the README file included with the examples for more information.
Step 4: Set permissions
The archiving pipeline must have read access to the catalog containing the stream layer, and read and write access to the catalog containing the index layer. Grant this access to the group ID under which the archiving pipeline will be created. For more information on how to grant access, see Share a Catalog.
Step 5: Deploy the application using a pipeline
To run the application, you must create a pipeline in the HERE Workspace. For more information, see:
Step 6: Verify the pipeline is running
In the HERE platform portal, select the Pipelines tab and find your pipeline. It should be in the Running state.
Querying indexed data
Once the archiving pipeline is running and data has been archived to the index layer, you can query and obtain data using one of the following methods:
Note
Make sure the app that's querying the index layer has read permission to the index layer. For more information, see:
For information on parsing the data retrieved from index layer, see: